
deeplearning学习笔记tensorflow_hellowolrd
一、深度学习过程代码
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import fashion_mnist_dataset_offline
print(tf.__version__)
#加载fashion mnist
fashion_mnist=keras.datasets.fashion_mnist
#print(fashion_mnist)
(trans_image,trans_lable),(test_image,test_lable)=fashion_mnist_dataset_offline.load_data_offline()
class_names = ['短袖圆领T恤', '裤子', '套衫', '连衣裙', '外套',
'凉鞋', '衬衫', '运动鞋','包', '短靴']
#打印结果集内容
print(trans_image.shape)
print(trans_lable.shape)
print(test_image.shape)
print(test_lable.shape)
# 创建一个新图形
plt.figure()
# 显示一张图片在二维的数据上 trans_image[0] 第一张图
plt.imshow(trans_image[0])
plt.figure(figsize=(10,10))
for i in range(36):
plt.subplot(6,6,i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(trans_image[i],cmap=plt.cm.binary)
plt.xlabel(trans_lable[i])
# 建立模型
def build_model():
# 线性叠加
model = tf.keras.Sequential()
# 改变平缓输入
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
# 第一层紧密连接128神经元
model.add(tf.keras.layers.Dense(128, activation=tf.nn.relu))
# 第二层分10 个类别
model.add(tf.keras.layers.Dense(10, activation=tf.nn.softmax))
return model
model=build_model()
#模型编译[optimizer优化器 loss损失衡量标准 metrics指标 accuracy精确度]
model.compile(optimizer=tf.train.AdadeltaOptimizer(),loss='sparse_categorical_crossentropy',metrics=['accuracy'])
#开始训练
history=model.fit(trans_image,trans_lable,epochs=5)
#结果衡量
test_loss,test_acc=model.evaluate(test_image,test_lable)
print('识别概率:',test_acc)
#引入pd
import pandas as pd
#历史概率
his_dataform=pd.DataFrame(history.history)
his_dataform.head()
his_dataform.plot(kind='line')
predictions=model.predict(test_image)
predictions[4]
np.argmax(predictions[4])
二、数据集问题的解决
因为数据集被qiang掉,所以自己搞了个线下读取数据包的方法。(线下数据包地址包含数字学习以及fashion学习 http://yann.lecun.com/exdb/mnist/)
from tensorflow.python.keras.utils import get_file
import gzip
import numpy as np
def load_data_offline():
base = "file:///G:/AI/fasion_mnist_dataset_offline/"
files = [
'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz'
]
paths = []
for fname in files:
paths.append(get_file(fname, origin=base + fname))
with gzip.open(paths[0], 'rb') as lbpath:
y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[1], 'rb') as imgpath:
x_train = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
with gzip.open(paths[2], 'rb') as lbpath:
y_test = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[3], 'rb') as imgpath:
x_test = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_test), 28, 28)
return (x_train, y_train), (x_test, y_test)
三、识别效果测试: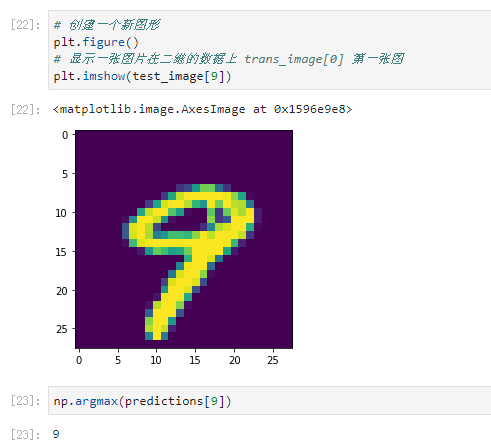
正文到此结束

热门推荐






相关文章
该篇文章的评论功能已被站长关闭




